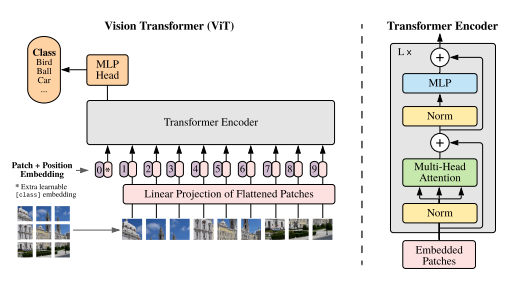
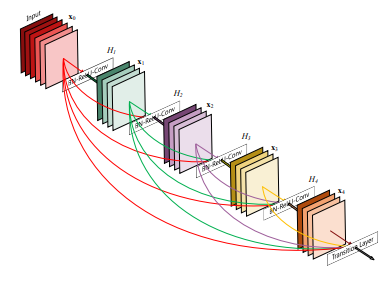
CNNs vs ViT
- Both CNNs and Transformers are prominent architectures in AI and ML.
- Following the success of language transformers, Vision Transformers (ViTs) are gaining popularity in computer vision.
- This study aimed to compare the performance of DenseNet and the Vision Transformer ViT-16 on an image classification and identification task using the Food101 dataset.
- The evaluation was based on common metrics like accuracy, F1 score, precision, and recall.